Designing a composite song recommendation system
Using data mining & analytics in R

Over the last few years, streaming has dramatically changed the music industry and revolutionized how we consume music. Now streaming accounts for the majority of recorded-music revenues. In fact, in 2019, streaming accounted for around 80% of recorded-music revenues[1]. The artists are increasingly relying on income from streaming platforms, especially after covid-19. We may still require work to achieve a sustainable healthy music ecosystem for both music creators and listeners. However, we must appreciate the impact streaming has had in driving the music industry’s growth.
Streaming services such as Spotify and Apple Music have achieved success by keeping the listeners engaged and managing the switching costs in their way. Apple raises the switching costs for users through its comprehensive ecosystem of services. Simultaneously, Spotify relies on keeping the user engaged through its algorithmic recommendation engine and delivering a more personalized experience. Apple Music also provides curated playlists, but Spotify leans more heavily on its recommendation system to retain customers. Spotify claims that its monthly engagement is twice, and the churn rate is half of that of Apple Music. Spotify’s Q3 2020 figures showed a monthly premium churn rate of less than 4% for the first time. So recommendation models have tremendous business value in retaining customers in the music streaming arena.
With that context, let’s build a song recommendation system using data mining and analytics in R. This composite system will mainly use unsupervised machine learning. It comprises three engines to recommend songs similar to those in the user library :
Engine-1: Recommend songs with similar audio features
Engine-2: Recommend songs with similar emotions in their lyrics
Engine -3: Recommend songs that are rated favorably by critics.
Dataset Introduction
Spotify for developers offers the possibility to utilize the audio features calculated for each song through its official Spotify Web API. We will use two variants of the Spotify song dataset.
For recommendation engine-1, which recommends songs based on similar audio features, we want as many observations as possible for better results. We will use a dataset with audio features of 232 thousand songs prepared by Zaheen Hamidani, accessible on Kaggle through this link: dataset-1.
For our engine 2, which recommends songs based on similar emotional sentiments in song lyrics, we will use a variant prepared by Farooq Ansari. This dataset originally contains 40 thousand songs from 1960-2019, but we will use only the dataset from 2010-2019 to deal with the computational challenge of text mining thousands of songs. This dataset has audio features of around 6300 songs and is accessible on Kaggle through this link: dataset-2.
We will use Genius API to get song lyrics of these 6000+ songs on top of this last dataset since there are no lyrics in the original dataset. We can create a developer account on the Genius developer website to get the API access keys. The Genius API allows only one song lyric to be accessed at a time through the R package ‘genius.’ So, we will write code to get lyrics of all songs in the dataset-2. The code below takes around 5 hours to acquire lyrics of about 6000 songs from the API. This computational intensity explains the choice of not going for a bigger dataset for engine-2.
# Function to extract lyrics
lyrics_s <- safely(geniusr::get_lyrics_id)
lyrics_search <- safely(geniusr::get_lyrics_search)
lyrics_new<-NULL
for(i in 1:length(spotify$track)){
lyrics_new[i] <- toString(lyrics_search(spotify$artist[i], spotify$track[i])$result$line)
}
For engine-3, there is no dataset available for song reviews, and web-scraping thousands of song reviews is a separate task on its own. Since this case intends to demonstrate the use-case, we will use a single song review from the Pitchfork website, copy it in a text file, and use it for further text mining.
Description of Dataset
Each song (row) in datasets 1&2 has values for artist name, track name, and the audio feature. Dataset-1 also has genre, popularity (0-100) & track ID tagged to songs. The song audio features in both datasets are named slightly differently but have the same meaning. The attributes are as follows:
duration_ms : The duration of the track in milliseconds.
key : The estimated overall key of the track. Integers map to pitches using standard Pitch Class notation . E.g. 0 = C, 1 = C♯/D♭, 2 = D, and so on. If no key was detected, the value is -1.
mode : Mode indicates the modality (major or minor) of a track, the type of scale from which its melodic content is derived. Major is represented by 1 and minor is 0.
acousticness : A confidence measure from 0.0 to 1.0 of whether the track is acoustic. 1.0 represents high confidence the track is acoustic.
danceability : Danceability describes how suitable a track is for dancing based on a combination of musical elements including tempo, rhythm stability, beat strength, and overall regularity. A value of 0.0 is least danceable and 1.0 is most danceable.
energy : Energy is a measure from 0.0 to 1.0 and represents a perceptual measure of intensity and activity. Typically, energetic tracks feel fast, loud, and noisy. For example, death metal has high energy, while a Bach prelude scores low on the scale. Perceptual features contributing to this attribute include dynamic range, perceived loudness, timbre, onset rate, and general entropy.
instrumentalness : Predicts whether a track contains no vocals. “Ooh” and “aah” sounds are treated as instrumental in this context. Rap or spoken word tracks are clearly “vocal”. The closer the instrumentalness value is to 1.0, the greater likelihood the track contains no vocal content. Values above 0.5 are intended to represent instrumental tracks, but confidence is higher as the value approaches 1.0.
liveness : Detects the presence of an audience in the recording. Higher liveness values represent an increased probability that the track was performed live. A value above 0.8 provides strong likelihood that the track is live.
loudness : The overall loudness of a track in decibels (dB). Loudness values are averaged across the entire track and are useful for comparing relative loudness of tracks. Loudness is the quality of a sound that is the primary psychological correlate of physical strength (amplitude). Values typical range between -60 and 0 dB and song becomes more loud as it approaches 0.
speechiness : Speechiness detects the presence of spoken words in a track. The more exclusively speech-like the recording (e.g. talk show, audio book, poetry), the closer to 1.0 the attribute value. Values above 0.66 describe tracks that are probably made entirely of spoken words. Values between 0.33 and 0.66 describe tracks that may contain both music and speech, either in sections or layered, including such cases as rap music. Values below 0.33 most likely represent music and other non-speech-like tracks.
valence : A measure from 0.0 to 1.0 describing the musical positiveness conveyed by a track. Tracks with high valence sound more positive (e.g. happy, cheerful, euphoric), while tracks with low valence sound more negative (e.g. sad, depressed, angry).
tempo : The overall estimated tempo of a track in beats per minute (BPM). In musical terminology, tempo is the speed or pace of a given piece and derives directly from the average beat duration.
popularity (only in dataset-1): It is the song popularity on Spotify with range from 0 to 100
genre (only in dataset-1): It is the tagged genre with each song through Spotify API
Data Cleaning & Preprocessing
We will follow the following steps to pre-process the data and ensure it is ready for analysis: import the dataset in R using the ‘read.csv’ function and check any NAs using ‘is.na’ function. No such observations are found for both datasets. We will filter the unique tracks using the ‘duplicated’ function. We will do Factoring for attributes such as key, mode, and genre to facilitate exploratory analysis. I also converted the duration from ms to minutes for better analysis.
spotify <- read.csv("SpotifyFeatures.csv")
spotify <- na.omit(spotify) # remove NA's
spotify <- spotify[!duplicated(spotify$track_id),] # remove duplicate tracks
# turn into factors
spotify$genre <- as.factor(spotify$genre)
spotify$mode <- as.factor(spotify$mode)
spotify$key <- as.factor(spotify$key)
#duration into min
spotify$duration_ms <- round(spotify$duration_ms/60000,3)
Exploratory Data Analysis (EDA)
Let’s analyze the distribution of the main audio features of 232k songs in the first dataset:

Observations from the histograms:
Danceability, energy, and valence are normally distributed.
Majority of observations in instrumentalness is not larger than 0.1, i.e., most of them are non-instrumental songs. Most songs are not recorded live with liveness less than 0.4. Majority of songs have speechiness less than 0.25 indicating that songs with less speech are more common.
Most songs have loudness between -5dB to -15dB. We can compare this with the recommended loudness from Apple Music (-16 dB), YouTube and Spotify (-14 dB) for online streaming.
For Song duration, we will check the outliers before making the boxplot. Only 1.1 % are found to be more than 10 min. They are clipped and the following boxplot is made.
#Drop outliers with duration >10min
percent<- count(spotify$duration_ms>10)$freq[2]/length(spotify$duration_ms)
clip<- prep_outliers(spotify$duration_ms, type='stop', method='bottom_top', top_percent = percent)
hist(clip, col = "coral", xlab="min", main="Song Duration")
As we can see majority songs lie between 3 to 5 min in duration.

Now let’s check the genres present in these songs:

The valence distribution based on genre was explored. Valence varies for every genre: Reggae & Children’s Music had highest valence. We can see valence plays a role in song audio.

We will further explore the top 5 genres in terms of popularity on Spotify: Pop emerges as the most popular genre, and Children’s music is the least popular. So high valence does not guarantee song popularity. Still, it can affect the kind of music people want to listen to.


Data Modeling
I. Recommendation Engine-1: Clustering based on audio features
We will work with dataset-1 here. The modeling methodology followed for this engine is as follows:
Normalize the selected audio features
Determine the optimal number of clusters for k-means
Perform k-means clustering
Interpret the clusters
Select user song based on which recommendations will be given
Model checks in which cluster does the user song belong
Give song recommendations from that cluster
The audio features selected for normalization are Acousticness, Danceability, Energy, Loudness, Speechiness, Instrumentalness, Liveness, Valence, and Tempo. The normalized selected fields are then saved in a new data frame. We will determine the optimal number of clusters using the elbow method.

As we cannot identify the elbow from the figure, we will test different clusters for k-means clustering and check how it impacts the goodness of fit score. The goodness of fit is calculated as (between sum of square / total sum of square). The closer it is to 100%, the better the clustering segregation is, i.e., clusters have more distinct characteristics. The Between Sum of Squares value signifies the ‘length’ from each centroid from each cluster to the global sample mean. The Total Sum of Squares value represents the ‘length’ from each observation to the global sample mean.
With n=5 clusters we get BSS/TSS = 54.9%. We shall increase it till n=7, after which the reduction in sum of squares plateaus down. We get BSS/TSS = 61% for 7 clusters. The next step is to perform k-means and find each cluster’s audio characteristics in the optimized model of seven clusters. The characteristics of each cluster are as follows:

We can characterize the clusters as follows:
Cluster-1 has the highest acousticness, lowest loudness & valence: ‘Sad Lounge.’
Cluster-2 has high acousticness, moderate danceability, and low energy: ‘Soft Dance.’
Cluster-3 has the lowest acousticness and high loudness: “Loud Dancing.’
Cluster-4 has the highest energy and most loudness: ‘Loud & Energetic.’
Cluster-5 has the highest instrumentalness, good danceability, and good energy: ‘Peppy Instrumentals.’
Cluster 6 has the lowest instrumentalness and highest speechiness & liveness: ‘Live Talk.’
Cluster 7 has the highest danceability and highest valence: ‘Happy & Dancing’
Recommendation from Engine-1:
We need to select a song based on which recommendations will be given. Let’s choose the track ‘Reflektor’ by Arcade Fire.
myselection<- spotify %>%
filter(track_name == "Reflektor", artist_name == "Arcade Fire")
mycluster<- myselection$cluster
mygenre<- myselection$genre
We then select ten songs from the cluster and genre where user selection lay. We can also give the condition of popularity greater than 70 to increase users’ chances of liking our recommendation.
spotify %>%
filter(cluster == mycluster,genre == mygenre, popularity>70) %>%
sample_n(10) %>%
select(cluster, artist_name,track_name,popularity, genre) %>%
formattable(align =c("l","l","l","c","c"))
This is the output from engine-1 for the final recommendation based on song audio features:

Adding the modularity of popularity in the recommendations above is a debatable thing. It highlights the small ways algorithms can affect how we discover music. We don’t want to create a system that de-emphasizes finding the less popular music or artists. That can lead to an engine that supports only popular music and is harsh on the broad spectrum of lesser-known artists. In that regard, we should not roll up recommendations on popularity. At the same time, such a system can have a higher chance of more engagement as people do want to listen to popular music that matches their taste. Making such decisions is one of the many finer points one should consider while building a recommendation system.
II. Recommendation Engine-2: Clustering based on song lyrics emotions (text mining)
We will work with dataset-2 here. The modeling methodology followed for this engine is as follows:
Prepare lyrics dataset by extracting lyrics of all songs in dataset-2 using Genius API
Prepare the data frame for text mining
Apply NRC emotion Lexicon for supervised learning
Normalize the lyrics sentiment values for all songs
Determine the optimal number of clusters for k-means
Perform k-means clustering
Interpret the clusters
Select user song based on which recommendations will be given
Model checks in which sentiment cluster does the user song belongs
Give song recommendations from that cluster
We will pre-process this dataset similarly as we did for the previous set. Then we will find the lyrics for each song using Genius API and create a new data frame with only the track name, track artist, and the lyrics. Now we will extract the sentiment of each song’s lyrics using the syuzhet R package, a sentiment extraction tool. This sentiment dictionary assigns text with emotions: anger, anticipation, disgust, fear, joy, sadness, surprise, trust. It also gives sentiments: positive & negative, but we will not use them for this engine.
We run sentiment analysis on each lyric and see the resulting data frame of sentiments.

We append this to the song name and artist to create a data frame ready for clustering. The sentiments are selected and normalized, and then we find the optimal clusters using the elbow method.

Again, the elbow is not visible, and we arrive at n=7 clusters for k-means clustering after trying various combinations. The goodness of fit is found to be 79.6%.
mining_kmeans <- kmeans(mining_scaled, centers = 7, nstart = 5)
((mining_kmeans$betweenss)/(mining_kmeans$totss))*100
We see the emotions in each cluster in our optimized model.

We can characterize the clusters as follows:
Cluster-1 highest anger, high fear, high sadness
Cluster-2 medium fear and anger
Cluster-3 almost no emotion, likely to be instrumentals with no lyrics
Cluster-4 low emotions but equally distributed
Cluster-5 most emotional cluster with a wide array of emotions
Cluster 6 medium anticipation, joy, and trust
Cluster 7 high trust and joy
Recommendation from Engine-2:
We select a song based on which recommendations will be given. Let’s choose the track ‘Shape of You’ by Ed Sheeran.
#Find where user preferences lie (which cluster)
myselection2<- mining_df %>%
filter(Track == "Shape Of You", Artist == "Ed Sheeran")
mycluster2<- myselection2$cluster
We find the lyrics of this song using the prepared text mining data frame. We load the lyrics as a corpus and then clean it using the tm_map function: convert to lowercase, remove punctuation, remove stopwords, strip whitespace, stemming. Then the tf-idf matrix is built. It is sorted on decreasing frequency. The most frequent words in the song lyrics are:

The wordcloud for ‘Shape of You’ lyrics is plotted.

Then the emotions associated with this song lyrics are plotted using the nrc_sentiment function. Trust and joy are high in this song lyrics.

We want to recommend songs that have similar emotions in their lyrics. We check where this song lies in our cluster created earlier and then make recommendations.
#Suggest new songs
mining_df %>%
filter(cluster == mycluster2) %>%
sample_n(10) %>%
select(cluster,Artist,Track) %>%
formattable(align =c("c","l","l"))
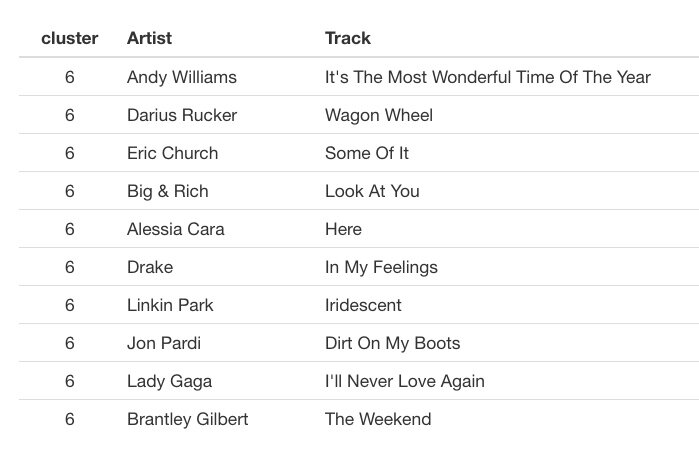
This is the final recommendation from engine-2 based on Shape of You lyrics:
III. Recommendation Engine-3: songs having positive critic reviews
We will do text mining on the Pitchfork song review by reading the text file contents and making the tf-idf matrix as we did in engine-2. The song review we will use can be accessed at this link: review. From the tf-idf matrix, we can see the most frequent words in the song review.



We will again use the syuzhet R package. This time, we will calculate the positive and negative sentiments associated with the song review words and ignore the emotional sentiments.
As the positive sentiment is higher, we can conclude that this was a positive review. We did this for one song to demonstrate the use case. We can do this at scale by using web scrapping for preparing a song reviews dataset and then create a weekly playlist for new songs getting positive reviews.
Learnings and Improvements
The combination of the three recommendation engines provides a system to keep the users engaged and explore new music to match their taste. A notable thing we can learn from such projects is that sometimes a single dataset may not be enough to help us achieve our goals. In that case, we need to access other datasets for additional properties or prepare our dataset as we prepared over here for song lyrics. Another point to note is that we are moving into the API economy. We should leverage various APIs available as they can help in accessing business-critical information needed to build new machine learning models.
There are still a lot of improvements possible in the recommendation system built. Some of the major ones are mentioned below:
We can do beta testing to find the ratio in which recommendations should be from engine-1 and engine-2 or see if they should be used on top of each other. The model which generates more user clicks should be selected, and we should regularly iterate this testing.
The engine-2 only does text mining of English lyrics now. For an ethical AI system, we need to be inclusive and handle other languages too.
The final recommendations can be modulated further on more parameters if they are made available. E.g., The year of song release was not available in the dataset. Still, if added, it can give another feature to roll on to provide song recommendations based on both user taste and recent release.
Endnotes
[1] Deloitte analysis based on data from “U.S. Sales Database,” the Recording Industry Association of America (RIAA); “CD” includes CDs and CD singles; “digital downloads” include downloaded albums, downloaded singles, ringtones and ringbacks, downloaded music videos, and other digital; “streaming” includes paid subscriptions, on-demand streaming (ad-supported), other ad-supported streaming, exchange distributions, and limited-tier paid subscriptions; “other formats” include LP/EP, vinyl singles, 8-track, cassettes, other tapes, SACD, DVD audio, music videos (physical), kiosk, and synchronization.